
Блиск і злидні Sive Base
Виконання фонетичної експертизи із застосуванням цього програмного комплексу викликає багато запитань
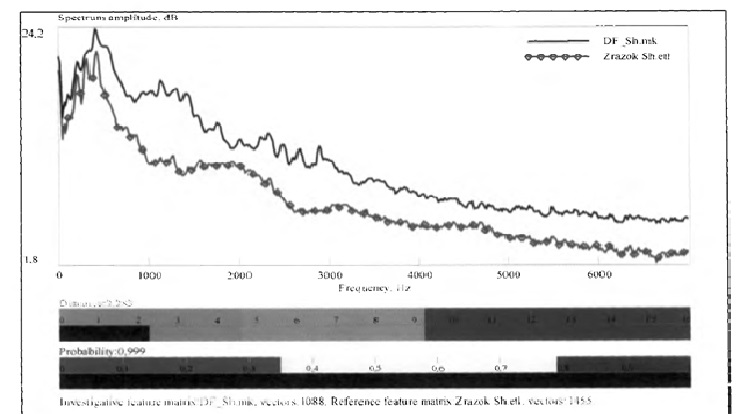
Приклад графіку порівняння АЧХ у Sive Base.
 СЕМЕН ХАНІН, адвокат, керуючий партнер юридичної компанії «АМБЕР», к.е.н., заслужений юрист України, член правління Асоціації адвокатів України
СЕМЕН ХАНІН, адвокат, керуючий партнер юридичної компанії «АМБЕР», к.е.н., заслужений юрист України, член правління Асоціації адвокатів УкраїниЗа результатами фонетичної експертизи часто вирішується доля людини. На практиці маємо, на жаль, зневажливе ставлення до описової частини таких експертиз з боку суддів, та ще більш зневажливе ставлення з боку експертів.
Частина1. (смак окремих інгредієнтів у супі»)
Наразі маємо справу з випадком, коли зазначене у висновку експерта викликає регіт, та судді все одно не бачать підстав для призначення повторної експертизи. Але якщо комусь з юристів все ж таки цікаво, то спробую максимально зрозуміло пояснити чому, наприклад, виконання вказаної експертизи із застосуванням програмного комплексу Sive Base викликає багато запитань.
Почну з того, що відповідна методика не зареєстрована у Міністерстві юстиції. Її, так вийшло, взагалі в Україні немає. Зареєстровано лише методичні рекомендації, що є лише інструкцією для користувача програми, та навіть вказані рекомендації чомусь для службового користування. Дуже смішно, наприклад, коли експерти пояснюють секретність вказаних рекомендацій. «Мов, начебто, якщо злочинець буде їх знати, він щось змінить у власному голосі таким чином, що зробить проведення експертизи неможливою».
«У кожної людини є унікальні фонетичні особливості голосу, вимови та артикуляції. Вони залежать від анатомічних особливостей голосового апарату та мовної практики. Незважаючи на можливі зміни в інтонації чи тембрі голосу, основні артикуляційні та просодичні особливості мовця залишаються відносно стабільними». Якщо б це було не так, то і фонетичної експертизи не існувало б. Ба більше, математичний апарат, що використовується, відомий досить давно. Так формула відстані Кульбака-Лейблера (Kullback–Leibler divergence, KL-divergence) була розроблена американськими математиками Соломоном Кульбаком (Solomon Kullback) і Річардом Лейблером (Richard Leibler) у 1951 році.
Для того, щоб перевірити описову частину експертного висновку, зрозуміло потрібна методика у наявності. Інакше, що ми перевіряємо? Ну, скажімо, помилився експерт. Це можливо? Як переконати суд у вказаній помилці, якщо методика невідома? Як суд тоді вникає в описову частину, особливо з урахуванням того, що жодний доказ не має наперед встановленої сили. Тобто наразі практично по всій країні судді звертають увагу лише на висновки експертизи, залишаючи дослідницьку частину поза увагою. Може тоді і треба, щоб експерт надавав сторонам та суду лише висновки? Бо у іншому разі, дуже важко бачити як дослідження експертизи у суді перетворюється на ганебне явище.
Повернемося до Sive Base. Та хоч методика та методичні рекомендації мені невідомі, але знайомі слова я там знайшов.
Спочатку експерт побудує порівняльну амплітудно-частотну характеристику досліджуваного зразку голосу та мовлення, та «еталонного» зразку. За наслідками такого порівняння він порахує Probability (вірогідність), що чомусь в українському перекладі буде зазначено як «узгодження голосів». Є дуже та дуже просте питання – а взагалі до чого тут теорія ймовірностей? Чи можливо її застосовувати у даному випадку?
Для того щоб застосувати теорію ймовірностей, подія має бути випадковою, повторюваною, мати визначений простір можливих результатів і підкорятися аксіомам Колмогорова. У даному випадку, коли маємо 2 зразки голосу та мовлення, яка подія випадкова? Тому теорія ймовірностей при фонетичному аналізі не застосовується, а застосовується математична статистика.
Чим відрізняється математична статистика від теорії ймовірностей?
|
Характеристика |
Теорія ймовірностей |
Математична статистика |
|
Що вивчає? |
Закони випадкових явищ і моделі ймовірностей. |
Методи аналізу даних на основі ймовірності. |
|
Що використовує? |
Абстрактні ймовірнісні моделі. |
Реальні вибірки та статистичні дані. |
|
Тип задач |
Визначення ймовірності подій, очікуваних значень, розподілів випадкових величин. |
Оцінка параметрів, перевірка гіпотез, прогнозування. |
|
Приклад |
Яка ймовірність випадання «орла» при підкиданні монети? |
Чи впливає зміна реклами на рівень продажів? |
Що цікаво далі. За графіками цих порівнянь можливо, наприклад, зробити формантний аналіз. Форманти – це піки в АЧХ (резонансні частоти голосового тракту). Основні форманти (F1, F2, F3) є стабільними для кожної людини, навіть якщо вона говорить голосніше чи тихіше. На графіку вони виглядають як висота, проведена з піку АЧХ на ось Х. Форманти порівнюються окремо для кожного звука (переважно голосних), оскільки вони є резонансними характеристиками голосового тракту під час вимови певного звука.
Чому аналізують форманти окремо для кожної букви (звука)?
Форманти — це резонанси голосового тракту, а його положення змінюється залежно від звука.
Різні голосні мають різні формантні структури — саме тому ми чуємо їх як різні звуки.
При порівнянні голосів важливо аналізувати однакові звуки — наприклад, якщо порівнювати звук [a] у двох записах, треба дивитися саме на його форманти, а не на випадкові шуми чи інші частотні компоненти.
Приклад (як відрізняються голосні):
[ɑ] («а» у слові father):
F1 ≈ 730 Гц, F2 ≈ 1090 Гц, F3 ≈ 2440 Гц
[i] («і» у слові meet):
F1 ≈ 270 Гц, F2 ≈ 2290 Гц, F3 ≈ 3010 Гц
[u] («у» у слові boot):
F1 ≈ 300 Гц, F2 ≈ 870 Гц, F3 ≈ 2240 Гц
Що ми побачимо на вказаних графіках порівняння АЧХ у Sive Base. Взагалі нічого. Ніяких формант. Та взагалі не зрозуміло, що було проаналізовано? АЧХ взагалі чого — усього файлу? Є якісь дві криві, які мають певну відстань одна від іншої. І так у засіданні усі подивилися на вказані малюнки, та пішли далі. Цікаво, а що потрібно намалювати, щоб це викликало непорозуміння?
Що відбувається при побудові АЧХ всього файлу? Графік буде містити сумарний спектр всіх звуків, які є у файлі.
Форманти, характерні для окремих голосних, будуть накладатися один на одного. Спектр буде містити не лише голосні, а й приголосні, шуми, паузи, що можуть ускладнити аналіз.
Приклад. Якщо у файлі вимовлено речення «Це тестовий запис», АЧХ покаже:
Спектр голосних [e], [o], [a], [i] — з їхніми формантами.
Спектр приголосних (які мають менше енергії, але все ще впливають на загальний спектр).
Шум (наприклад, фоновий або від дихання).
Чому це проблема для формантного аналізу?
Форманти різних голосних змішуються, і стає складно розрізнити, які частотні піки відповідають конкретним голосним.
Приголосні звуки мають інший спектр, що може спотворювати загальний вигляд АЧХ.
Якщо у файлі є різні голосні, вони мають різні формантні частоти, що може робити побудову єдиної формантної структури некоректною.
Аналогія: Уяви, що ти намагаєшся зрозуміти смак окремих інгредієнтів у супі, але всі вони змішані. Визначити точні характеристики кожного компонента складніше, ніж якби вони були окремо.
Як правильно будувати АЧХ для формантного аналізу? Щоб отримати коректні форманти, краще:
розбити запис на голосні звуки (наприклад, за допомогою спектрограм або вручну);
будувати АЧХ окремо для кожного голосного;
фільтрувати приголосні — їхній внесок у загальний спектр не такий важливий.
Методи покращення аналізу:
використання спектрограми — дозволяє побачити форманти в часі та виділити їх для конкретних голосних.
фільтрація частот — дозволяє прибрати шуми та виділити основні резонанси.
автоматичне розпізнавання голосних — нейромережі можуть автоматично розбивати сигнал на окремі голосні перед аналізом.
Для точного аналізу формант мовця потрібні окремі графіки АЧХ для кожної голосної. Оскільки кожен голосний звук має свою унікальну формантну структуру, їх не можна порівнювати без урахування конкретного звука. Для кожного запису для однієї і тієї ж букви одного мовця форманти можуть суттєво відрізнятися, але відстань між формантами є унікальною для кожної людини. Вона, ця відстань, і порівнюється для визначення мовця.
Але кого це все цікавить? Якщо намалювати дві криві, то для суду це достатньо. І для вироку теж.
Частина 2. (поміряємо що завгодно, та що небудь порахуємо)
Я, як і усі люблю посміхнутися. Але коли вирішується доля людини, сміятися мають усі, або ніхто.
Для визначення мовця, тобто для порівняння голосу та мовлення диктора на зразку 1 та зразку 2, за допомогою програмного комплексу Sive Base експерт проводить аналіз ідентифікаційних ознак фономатеріалу, в тому числі будує Voice clarity histograms.
Voice Clarity Histogram — це гістограма, яка використовується для аналізу та візуалізації якості голосового сигналу, зокрема його чіткості. Вона дозволяє оцінити, наскільки розбірливим і зрозумілим є голос у записі чи в реальному часі.
Обмеження Voice Clarity Histogram у порівнянні мовців
Не дає унікального голосового «відбитку». Вона показує лише розподіл рівня чіткості мовлення, а не унікальні голосові особливості (наприклад, тембр, форманти, спектрограми).
Чутливість до зовнішніх факторів
Якщо якість запису різна (наприклад, один запис зроблено в шумному місці, а інший — у тиші), це може спотворити результати. Мовець може говорити чіткіше або менш чітко залежно від обставин.
Не враховує інші біометричні параметри голосу
Для точної ідентифікації мовця зазвичай використовуються мел-кепстральні коефіцієнти (MFCC), голосові форманти, тональний аналіз (pitch analysis) та глибокі нейронні мережі.
На практиці вказані зразки завжди записані у різній якості. Так як Зразок 1 зазвичай отримано унаслідок НСРД, наприклад завдяки диктофону «Москіт», та запис йде з великим зовнішнім шумом вулиці, чи звичайних шумів при спілкуванні у ресторані, то Зразок 2 зазвичай орган досудового розслідування отримує за наслідком судового засідання, наприклад обрання міри запобіжного заходу, де запис мовця йде на зовсім інше обладнання, в іншому форматі, з іншим кодеком, та практично без зовнішніх шумів. Навіть не спеціалісту зрозуміло, що якість звукового сигналу буде завжди відрізнятися суттєво, тобто яке значення вказаної гістограми для аналізу залишається незрозумілим.
Я пригадав анекдот з дитинства.
Василь гукає до Петра: «Прибор?»
Петро: «П’ять!»
Василь: «Що п’ять?»
Петро: «А що прибор?»
Тобто поміряємо що завгодно, та що небудь порахуємо.
Усім мабуть цікаво, а що та в яких одиницях виміряно. По осі «Y» на вказаних гістограмах взагалі нічого не зазначено, а по осі «Х» стоять якісь магічні цифри — 13.7, 210.5, 407.4, 604.3, 801.2, 998.0.
Що найбільш ймовірно? Найімовірніше, що значення по осі X – це нормалізований індекс чіткості голосу у відносних одиницях (scaled clarity score, 0—1000).
Низькі значення (~13.7—100) можуть означати низьку чіткість (шум, погана дикція, ефекти реверберації). Високі значення (~900—1000) можуть означати високу розбірливість.
Найвірогідніше, що по осі Y — це кількість фрагментів мовлення (частота випадків), у яких зустрічається певний рівень Voice Clarity (X).
Низькі значення Y означають, що деякі рівні чіткості зустрічаються рідко. Високі значення Y означають, що певний рівень чіткості спостерігається дуже часто.
Висновок:
X (горизонтальна вісь) = рівень чіткості голосу (scaled clarity score, 0—1000);
Y (вертикальна вісь) = кількість сегментів мовлення (частота появи певного рівня clarity score).
Чим більше значення Y у високих X, тим якісніше мовлення у записі.
Далі у порівняльній гістограмі зазначені певні статистичні характеристики:
1. Мінімум
2. Максимум
3. Mean (середнє), яке перекладається як «математичне очікування»
Що означає Mean у нашій гістограмі?
Mean = 201.40 (для Zrazok Sh.ton)
Середня чіткість голосу у першому записі вища, ніж у другому. Це означає, що голос в середньому був більш розбірливий.
Mean = 175.29 (для DFSh.ton)
Чіткість голосу в цьому записі нижча, ніж у першому. Це може вказувати на більш глухе або менш чітке мовлення.
4. Deviation (відхилення) — означає, наскільки певні значення відрізняються від (mean)
Порівняння Deviation у нашій гістограмі:
Zrazok Sh.ton → Deviation = 175.34
→ Чіткість голосу змінюється більш варіативно, можливі різкі переходи між дуже чіткими і менш чіткими сегментами.
DFSh.ton → Deviation = 92.27
→ Голос стабільніший за чіткістю, менше варіацій у вимові.
Висновок:
Якщо Deviation більше → голос нестабільний по чіткості.
Якщо Deviation менше → голос стабільний по чіткості.
5. Skewness (асиметрія) – це статистична міра, яка показує, наскільки розподіл даних відхиляється від симетричного (нормального) розподілу. Вона вказує на нахил або перекіс розподілу відносно середнього значення.
У нашій гістограмі:
Zrazok Sh.ton → Skewness = 1.93 → Правобічний перекіс (більшість значень низькі, але є довгий хвіст вправо).
DFSh.ton → Skewness = 0.63 → Майже симетричний розподіл (чіткість голосу розподілена більш рівномірно).
6. Curtosis – це коефіцієнт ексцесу, який описує, наскільки «гостроверхий» або «плоский» розподіл даних порівняно з нормальним розподілом.
Що означає Curtosis у нашому випадку?
Zrazok Sh.ton (Curtosis = 7.16)
→ Розподіл дуже гостровершинний.
→ Голос має переважно стабільну чіткість, але зрідка трапляються дуже різкі коливання (дуже нечіткі або дуже чіткі моменти).
DFSh.ton (Curtosis = 3.79)
→ Розподіл більш нормальний, менш гостровершинний.
→ Чіткість голосу розподілена рівномірніше, без різких змін.
Висновок:
Zrazok Sh.ton → Дуже різка концентрація чіткості мовлення біля певного значення, але іноді бувають екстремальні відхилення.
DFSh.ton → Голос більш рівномірний за чіткістю, без різких «стрибків» у крайніх значеннях.
7. Coincidence (співпадіння, коефіцієнт збігу) у нашій гістограмі означає ступінь подібності між двома розподілами чіткості голосу (Voice Clarity Score) для Zrazok Sh.ton та DFSh.ton.
Як інтерпретувати Coincidence?
Коефіцієнт Coincidence = 0.6608 зазвичай має значення від 0 до 1. Якщо Coincidence = 1, це означає, що обидва розподіли ідентичні (чіткість голосу розподілена однаково для обох мовців/ записів). Якщо Coincidence = 0, це означає, що немає жодного збігу між двома розподілами.
Якщо Coincidence = 0.6608, це означає, що ці розподіли мають середню подібність (вони не ідентичні, але мають значну схожість).
Що означає значення 0.6608 у нашому випадку?
Розподіл чіткості голосу між двома записами має схожі характеристики, але не є повністю однаковим. Деякі діапазони чіткості голосу (X) мають схожі частоти (Y), але є відмінності у крайніх значеннях або загальному розподілі.
Висновок: якщо аналізується один і той же мовець, це може свідчити про різну якість запису або зміну мовлення в різних умовах. Якщо аналізуються різні мовці, то вони мають певну подібність у чіткості мовлення, але їх голоси не ідентичні.
8. Correlation (кореляція) — це статистична міра, яка показує ступінь зв’язку між двома розподілами чіткості голосу (Voice Clarity Score) у записах Zrazok Sh.ton та DFSh.ton.
9. Відстань Кульбака-Лейблера (KL-Divergence, KL-відстань) — це міра відмінності між двома розподілами. Вона показує, наскільки інформація в одному розподілі відрізняється від іншого.
Як інтерпретувати KL-Divergence?
Якщо KL = 0, це означає, що обидва розподіли ідентичні. Чим більше значення KL, тим сильніше розподіли відрізняються.
Значення 0.8032 означає, що розподіли мають суттєві відмінності, хоча вони не абсолютно різні.
10. Common Coefficient (загальний коефіцієнт) — це узагальнена міра подібності.
У математичній статистиці немає єдиного стандартного методу обчислення Common Coefficient, оскільки він залежить від контексту. Найчастіше використовуються 5—7 підходів, але можна створити й більше, комбінуючи різні міри подібності. Тут ми нічого без методики не вгадаємо.
Які суперечності у нашій гістограмі?
1. Висока кореляція (0.9164) при середньому збігу (0.6608)
Кореляція 0.9164 означає, що обидва голоси змінюються схожим чином. Але Coincidence 0.6608 означає, що вони не ідеально збігаються у частотному розподілі. Це означає, що голоси можуть мати схожий патерн змін, але різні піки або варіативність.
Чому це може бути суперечливим? Якщо кореляція дуже висока, ми очікували б, що збіг (Coincidence) буде ще вищим (~0.85+). Ймовірно, є різниця у частоті появи певних значень чіткості голосу. Це може свідчити про стилістичні або технічні відмінності між записами (наприклад, один голос більш рівномірний, інший має сплески в чіткості).
2. Висока асиметрія (Skewness = 1.93 для Zrazok Sh.ton) при високій чіткості голосу (Mean = 201.40).
Висока асиметрія (1.93) означає, що більшість значень знаходиться в нижній частині шкали, а є рідкісні дуже високі значення. Але Mean = 201.40 означає, що в середньому голос досить чіткий.
Чому це може бути суперечливим? Якщо голос у середньому чіткий, ми очікували б меншу асиметрію, тобто рівномірний розподіл значень. Але висока асиметрія означає, що в записі є дуже багато низьких значень чіткості та поодинокі дуже високі значення. Це може означати неоднорідний запис (деякі частини дуже розбірливі, деякі – ні) або наявність шуму.
3. Високий ексцес для Zrazok Sh.ton (Curtosis = 7.16) при нестабільному голосі (Deviation = 175.34).
Curtosis = 7.16 означає дуже гостровершинний розподіл → більшість значень скупчені в одному місці, але є рідкісні екстремальні значення.
Deviation = 175.34 означає, що чіткість голосу сильно змінюється у записі.
Чому це може бути суперечливим?
Якщо Curtosis високий, це означає, що розподіл вузький, тобто більшість значень повинні бути близькі один до одного. Але якщо Deviation також високе, це означає, що є багато розкиданих значень. Це може означати нестабільний голос, де більшість часу голос стабільний, але є окремі моменти дуже сильних змін (наприклад, шум, перепади гучності, перешкоди в записі).
4. KL-Divergence (0.8032) при високій кореляції (0.9164)
Висока кореляція (0.9164) означає, що два голоси змінюються однаково. Але KL-Divergence = 0.8032 означає, що розподіли містять значну кількість унікальних особливостей.
Чому це може бути суперечливим? Якщо два голоси корелюють майже на 1, ми очікували б дуже малу KL-відстань (~0.2-0.3). Але KL = 0.8032 показує, що є істотна різниця у розподілах. Це може означати, що голоси змінюються схожим чином (кореляція), але мають різну варіативність та унікальні особливості (наприклад, один голос більш рівномірний, інший має сильні сплески).
Тобто, аналізуючи вказану порівняльну гістограму за умови запису голосу та мовлення в однакових умовах експерт мав би прийти к висновку, що це два різних мовця.
У нашому випадку, коли DFSh.ton отримано унаслідок НСРД, наприклад завдяки диктофону «Москіт», а Zrazok Sh.ton орган досудового розслідування отримав за наслідком судового засідання, де запис мовця йшов на зовсім інше обладнання, в іншому форматі, з іншим кодеком, згадане порівняння взагалі безглузде.
Але експерт ще прийшов до висновку, що голос та мовлення на обох записах належать одному мовцю. З таким успіхом по згаданим записам експерт міг ще оцінити колір волосся.
Як то кажуть, чекаємо в наступних експертизах!
Частина 3. (для мене і ведмідь не прокурор, і хеш-сума не контрольна сума)
Поганий той експерт, хто хоч раз не порахував контрольну суму. Фактично він міг просто порахувати 1, 2, 3… Але ні, людина з освітою, тому контрольна сума файлу згідно з алгоритмом підрахунку SHA-256 (хеш-сума). Але для нас, юристів-математиків, і ведмідь не прокурор, і хеш-сума не контрольна сума.
|
По-перше,
Атака розширення довжини (Length Extension Attack) на SHA-256
Атака розширення довжини (Length Extension Attack) дозволяє зловмиснику додати нові дані до хешованого повідомлення.
Чому це можливо?
SHA-256 обробляє вхідні дані блоками і використовує проміжні хеш-значення як стартову точку для наступних блоків.
Як працює SHA-256?
Повідомлення ділиться на 512-бітні блоки. Кожен блок обробляється по черзі, використовуючи попереднє хеш-значення. У фіналі ми отримуємо остаточне хеш-значення.
Але якщо зловмисник знає SHA-256 (секрет || повідомлення), він може «продовжити» хешування, використовуючи це проміжне значення як початковий стан для нового блоку!
Висновок:
Length Extension Attack дозволяє зловмиснику додавати нові дані до вже хешованого повідомлення без знання секрету.
Це можливо в SHA-256, бо він використовує конструкцію Merkle-Damgård, де можна продовжити хешування з проміжного стану.
По-друге, є велика відмінність між хеш-сумою та електронно-цифровим підписом, який передбачений для електронних документів законом «Про електронні документи та електронний документообіг».
Різниця між електронно-цифровим підписом (ЕЦП) і хеш-сумою
Електронно-цифровий підпис (ЕЦП) — це криптографічний механізм автентифікації та гарантія цілісності даних.
Хеш-сума — це контрольне значення для перевірки цілісності даних, але без прив’язки до конкретного автора та дати (часу) створення контрольної суми.
Основна різниця:
Хеш-сума просто показує, що дані не змінилися, але не підтверджує, хто та коли їх створив.
ЕЦП не лише перевіряє цілісність даних, а й підтверджує авторство (підписанта) за допомогою криптографії з відкритим ключем, та дату (час) створення підпису.
Ось і виходить, що контрольна сума файлу згідно з алгоритмом підрахунку SHA-256, що порахована експертом, нічого нам не дає. Незрозуміло, чи було файл змінено до того, як він попав до експерта? Незрозуміло, хто саме розрахував хеш-суму? Незрозуміло, коли ця хеш-сума була розрахована — в час, коли файл потрапив до експерта, чи коли файл можливо був спотворений експертом, а потім розрахована хеш-сума?
Незрозуміло, чи не був файл спотворений вже після проведення експертизи та обрахунку хеш-суми невідомими особами з використанням Length Extension Attack SHA-256?
Частина 4, остання. (Україна — не Литва)
У мене є стійке переконання, можливо помилкове, що справа з Sive Base розпочалася за наступним сценарієм. Є такий Шална Б. – старший спеціаліст відділу фоноскопічних експертиз Центру Судової експертизи Литви, доктор технічних наук. Він створив певну методику, скажімо з назвою Sive Base. Але після того, як до складу авторів приєдналися ще декілька громадян України, її стали активно купувати певні українськи експертні установи. Тому автори є, а методики немає.
Та хай би йому грець, але виникає важлива деталь: Україна - не Литва. Тобто (вірогідно) навчали коректно працювати цю модель на литовській мові, а використовують для української та російської мов. На скільки це суттєво? Дуже суттєво, так як створює дві невирішені проблеми — фоноскопічну та математичну.
Проблеми при використанні методики та ПЗ для фоноскопічного аналізу литовської мови на українській та російській мовах
Якщо фоноскопічна система була навчена для литовської мови, але використовується для української та російської мов, це може викликати серйозні проблеми у точності аналізу. Основні проблеми пов’язані з фонетичними, артикуляційними, спектральними та мовними особливостями.
Відмінності у фонетиці та фонології
Фоноскопічний аналіз орієнтується на особливості мовлення, зокрема на тембр, артикуляцію, ритміку, форманти та спектр голосу.
Ключові проблеми:
різний набір звуків:
литовська мова містить довгі голосні, яких немає в українській чи російській мовах.
Українська має м’які «д», «т», «л», «н», що відсутні в литовській мові.
Російська має редукцію голосних, якої немає в литовській та українській.
Відмінності в наголосі та інтонації:
литовська мова має тональний наголос, що суттєво впливає на аналіз тембру та мелодики мовлення.
В українській та російській мовах наголос динамічний і змінний, що змінює довжину голосних та частотні характеристики.
Різна структура слів:
у литовській багато слів відкритої структури (голосний-приголосний-голосний), а в українській і російській багато закритих складів, що змінює темп і спектральні характеристики голосу.
Наслідки:
алгоритми можуть помилково ідентифікувати мовця, оскільки аналіз звуків базується на литовській моделі;
помилки у порівнянні голосів через нерелевантні акустичні параметри.
Спотворення тембральних характеристик (Timbre & Formants)
Тембр голосу значною мірою залежить від формантних частот F1, F2, F3.
В українській та російській мовах співвідношення між голосними зовсім інше, ніж у литовській.
Литовська мова має ширший частотний діапазон голосних, що може змінювати алгоритмічне розпізнавання голосу.
Наслідки:
якщо модель навчена на литовській, вона неправильно класифікуватиме форманти голосних в українській і російській мовах;
тембр може здаватися іншим, що призведе до помилкового розпізнавання мовця.
Проблеми з порівнянням голосів у базах даних
Якщо база для порівняння створена для литовських мовців, порівняння з українськими та російськими записами буде некоректним.
Блоки Pitch Histogram, Timbre, Max Harmonics, Voice Clarity будуть спотворені через невідповідність моделей.
Проблеми динамічного порівняння мовлення (Dynamic Time Warping, DTW) через різну довжину голосних і ритміку.
Наслідки:
голоси можуть не співпадати навіть якщо це одна й та сама людина;
або навпаки, дві різні особи можуть бути помилково ідентифіковані як одна.
Вплив на автоматичне розпізнавання мовлення (ASR, STT)
Якщо ПЗ має вбудоване автоматичне розпізнавання мовлення (ASR, Speech-to-Text), воно може неправильно транскрибувати українську та російську мови через невідповідність фонемної моделі.
Українська мова має більше дифтонгів та м’яких приголосних, ніж литовська.
Російська мова має звукову редукцію, яку литовська не використовує.
Наслідки:
неправильне розпізнавання слів вплине на загальний фоноскопічний аналіз;
це може спотворити аналіз швидкості мовлення, ритміки та пауз, які є важливими для ідентифікації голосу.
Відмінності у фонетичному спектрі шумів та артефактів запису
В литовській мові менше шумових приголосних, ніж в українській та російській.
Шиплячі звуки («ш», «ч», «ж», «щ») мають інший спектральний розподіл в різних мовах.
Алгоритми, які визначають шумові профілі, можуть некоректно впливати на спектральний аналіз голосу.
Наслідки:
шумоподавлення та спектральна фільтрація можуть працювати некоректно;
голосові записи з шумами можуть ідентифікуватися по-різному в залежності від мови.
Відмінності в інтонації та просодії
Литовська мова має тональну інтонацію, яку не мають українська та російська.
Українська мова мелодійніша за російську, а російська має монотонніший ритм.
Наслідки:
алгоритм може неправильно інтерпретувати інтонаційні особливості, що вплине на розпізнавання мовця;
голосові спектрограми можуть давати хибні збіги або відмінності.
Технічні та методологічні проблеми
Фоноскопічні бази для литовської мови не включають особливості української та російської.
Стандарти формування голосових зразків відрізняються (різний набір тестових слів, фраз для аналізу).
Помилки в статистичних методах порівняння, якщо модель побудована на неправильних вибірках.
Наслідки:
може знадобитися повна переадаптація моделі під українську та російську мови;
результати можуть бути некоректними або неправомірними в судовій експертизі.
Висновки та можливі рішення
Основні ризики:
зниження точності ідентифікації мовця через мовні відмінності;
хибні позитивні або негативні результати при порівнянні голосів;
невідповідність статистичних та спектральних характеристик голосу;
методологічні помилки через невідповідність моделі мові дослідження.
Математична проблема
Що юрист знає про теорію ймовірностей. Юрист знає про частотну теорію, яка каже, що якщо дуже довго підкидувати монету в гору, то кількість разів, коли випаде орел, та випаде решка буде практично однакова. І юрист знає, що можливо казати про вірогідність 50% випадіння орла. І для цієї статті ми не будемо розширювати ці знання.
Але, окрім частотного підходу, є ще Баєсова інтерпретація вірогідності, коли ймовірність відображає ступінь довіри до події.
Програмні комплекси, що працюють при ідентифікації по голосу та мовленню, працюють з Баєсовою інтерпретацією вірогідності, тобто дещо з іншою вірогідністю, незрозумілою та незвичною для юристів.
Хай у нас є мішок з шарами – червоними та білими. Але нам не відомо як про кількість шарів, так і про співвідношення червоних та білих шарів. Ми виймаємо шар з мішка, записуємо його колір, та кладемо назад. Робимо висновок відносно співвідношення білих та червоних шарів. Далі знов витягаємо шар! Але вже ми змінюємо свою гіпотезу з урахуванням попереднього результату. І так, поки не втомимося. Тобто ми змінюємо свою гіпотезу кожний раз з урахуванням попередніх досліджень, з кожним вимірюванням роблячи гіпотезу кращою. Між іншим, результат такого дослідження математики називають умовною вірогідністю.
Маленьке зауваження. Вірогідність кожного разу витягнути червоний чи білий шар не залежить від попередніх спроб. Якщо, наприклад, червоних шарів – 40, а білих 60, то вірогідність кожний раз витягнути червоний шар – 40%. Але ми ж не знаємо як шари розфарбовані. І кожного разу, витягуючи шар, ми змінюємо свою гіпотезу про кількість червоних та білих шарів з урахування результату експерименту та попередніх результатів випробувань, відповідно змінюється умовна вірогідність. Але відображає вона дещо інше. На нашому прикладі, можливо уявити графік у вигляді ДЗВОНУ, де вершина дзвону – буде максимальною вірогідністю події, що червоних шарів 40%, а сторони дзвону, що йдуть до низу, вірогідність іншого співвідношення.
Про неочевидні речі. Або як виграти справу про наркотики.
Кожний тест на наркотики не ідеальний.
У тесту є така властивість як чутливість, що означає вірогідність того, що людина, яка дійсно приймає наркотики буде виявлена тестом. Хай така чутливість – 97%.
У тесту є така властивість як специфічність, що означає, вірогідність того, що людина, яка не приймає наркотики буде відображена тестом як така що не приймає наркотики. Хай така специфічність – 95%.
(Звертаю вашу увагу, що наслідками тесту може бути не 2, а 4 результати:
Людина приймає наркотики, та тест її виявив;
Людина приймає наркотики, та тест це не виявив;
Людина не приймає наркотики, але тест помилився, та показав що приймає;
Людина не приймає наркотики, та тест це підтвердив).
Ще дуже важливий показник, це показник раніше проведених досліджень (як з шарами). Наприклад, ми перевірили усю країну, та встановили, що 0.5% громадян приймають наркотики. Тобто, якщо б ми випадковим чином вибрали людину з усіх громадян країни, то з вірогідністю 0.5% вона наркоман.
Тоді, оцінюючи результати тесту, який дав відповідь про наркозалежність людини, ми повинні застосувати нові знання про умовну вірогідність, яка розраховується наступним чином:
0.97 x 0.005 / (0.97 x 0.005 + (1-0.95)x(1-0.005))=0.09,
тобто справжня можливість бути наркоманом з позитивним результатом цього тесту становить лише 9%, а не 97% - як зазвичай у судовому засіданні псевдоексперт та дефектив скажуть судді! Ось що таке Баєсова інтерпретація вірогідності, та її відмінність від частотної теорії.
Про фоноскопічну експертизу
Пошукайте у Google стосовно програмного комплексу Sive Base. Там побачите наступне:
«Програмний комплекс для ідентифікації людини по голосу та мовленню SIVE Base використовується для визначення та порівняння параметрів голосу мовця об`єктивним способом з метою відображення статистичного розподілу відповідних параметрів на діаграмах і розрахування коефіцієнту кореляції між цими діаграмами….SIVE VOICE – програмний комплекс для автоматичного пошуку досліджуваного голосу в заданому наборі файлів, що містять зразки голосів, на основі Баєсовської оцінки».
Ой, як цікаво!!!!!
Наскільки важливі результати попередніх досліджень для Баєсовської оцінки ми вже зрозуміли на прикладі тесту на наркотики. Тут така сама справа. Програмний комплекс навчають, та потім перевіряють це навчання, на певній групі осіб. Не потрібно бути лінгвістом, щоб зрозуміти наскільки ця група є визначальною. Хто ці люди, які навчали модель? Вони були англомовні? Вони були російськомовні? Вони розмовляли українською, але це не була їх рідна мова? Як ці люди відрізнялися за віком та статтю? Скільки було осіб у згаданій групі? Без відповіді на ці питання використання певного програмного комплексу є лише шарлатанством.
А це ще далеко не усі запитання. А як було записано експериментальний та контрольний зразки, однією технікою чи різною? Частота дискретизації? Розмір глибини бітів?
Тобто, що відбулося. Простою мовою.
За допомогою перетворення Фур’є запис з голосом та мовленням Особи розкладають на прості гармоніки по частотам. (Це як у школі біле світло завдяки призмі розкладають на спектр).
Далі за допомогою, наприклад, відстані Кульбака — Лейблера на основі тестової групи осіб навчають певну модель ідентифікувати Осіб по голосу та мовленню. (За допомогою лінійки вимірюють різницю у рості між людьми, та відбирають максимально схожих за ростом).
І це дійсно наука – математика.
Потім йде певне шарлатанство на етапі створення програмного комплексу, а саме шарлатанство полягає у відсутності відповідей на раніше зазначені питання. Крім того, насправді, є ще дуже велика кількість запитань: технічні характеристики запису та їх вплив на чутливість та специфічність методу та інше. Все це добре розуміється математиками, але сумлінно приховується експертами, що використовують такі програмні комплекси. Та за допомогою цієї АБВГДейки вирішується доля людей та працює наше правосуддя.